
가상 메모리 매커니즘
- (1) 메인 메모리를 디스크에 저장된 주소공간에 대한 캐시로 취급해서 메인 메모리 내 활성화 영역만 유지하고, 데이터를 디스크와 메모리 간에 필요에 따라 전송하는 방법으로 메인 메모리를 효율적으로 사용
- (2) 각 프로세스에 통일된 주소공간을 제공함으로써 메모리 관리를 단순화
- (3) 각 프로세스의 주소공간을 다른 프로세스에 의한 손상으로부터 보호
가상메모리를 이해해야 하는 이유
- 가상메모리는 중요함 : 가상메모리는 컴퓨터의 모든 수준의 시스템에 스며들어 있음. 가상메모리를 이해하면 어떻게 시스템이 동작하는지 이해할 수 있음.
- 가상메모리는 강력함 : 가상메모리는 응용에 메모리 블록 생성, 제거, 디스크 파일에 메모리 블럭 매핑, 다른 프로세스들과 메모리 공유 등 강력한 기능을 제공함. 메모리 위치에서 읽고 쓰는 것으로 디스크 파일의 내용을 수정하거나 읽을 수도 있음.
- 가상메모리는 위험함 : 변수 참조, 포인터 역참조 등 할 때마다 가상메모리와 상호작용함. 이런거 잘못하면 메모리 관련 버그 나거나, 심지어는 잘못된 결과로 프로그램이 끝까지 실행될 수 있음.
9.1 물리 및 가상주소 방식 (Physical and Virtual Addressing)
물리 주소 : 실제 하드웨어 메모리의 특정 위치를 나타내는 주소
가상 주소 : 프로세스가 사용하는 주소 공간
주소 변환 : 가상 주소를 물리 주소로 변환. MMU(Memory Management Unit)라는 하드웨어 컴포턴트에 의해 변환됨.
페이지 테이블 : 가상 주소를 물리 주소로 매핑하는 데 사용되는 데이터 구조
페이지 결함 : 페이지 테이블 탐색 중에 유효 비트가 설정되지 않음. 해당 가상 페이지가 현재 물리 메모리에 없음을 의미.
9.3 캐싱 도구로서의 VM (VM as a Tool for Caching)
가상메모리는 디스크에 저장된 N개의 바이트 크기의 셀 배열로 구성됨.
각 바이트는 특정한 가상주소를 가지며, 배열의 인덱스로 작용함.
디스크 안의 배열 정보는 메인 메모리에 캐시됨.
9.3.1 DRAM 캐시의 구성
캐시 미스 (cache miss) : 요청된 데이터가 캐시에 존재하지 않아 더 상위 수준의 메모리에서 데이터를 가져와야 하는 상황
미스 페널티 (Miss Penalty) : 캐시 미스가 발생했을 때 데이터를 상위 수준의 메모리(즉, 더 느리고 더 큰 메모리)로부터 가져오는 데 소요되는 추가 시간 또는 지연
캐시 미스 종류
- 일차 캐시 미스(First-level Cache Miss): CPU의 일차 캐시(L1 캐시)에서 요청한 데이터를 찾을 수 없는 경우
- 이차 캐시 미스(Second-level Cache Miss): L1 캐시에서 데이터를 찾지 못해 L2 캐시를 참조했지만, L2 캐시에도 데이터가 없는 경우
- 메모리 미스(Memory Miss): L2 캐시에도 데이터가 없는 경우 메인 메모리(DRAM)를 참조해야 하는 경우
미스 페널티 구성 요소
- 메모리 접근 시간: 요청한 데이터를 상위 메모리(예: 메인 메모리, 디스크)로부터 가져오는 데 필요한 시간
- 전송 시간: 데이터를 상위 메모리로부터 캐시로 전송하는 데 걸리는 시간
- 캐시 업데이트 시간: 가져온 데이터를 캐시에 저장하고, 필요한 경우 기존 데이터를 무효화하는 데 걸리는 시간
가상 메모리는 디스크에 저장되는 N개의 연속적인 바이트들로 이뤄진 배열을 의미하며, 해당 바이트 배열의 일부는 메인 메모리(DRAM 캐시)에 캐시됨.
캐시 메모리가 메인 메모리의 캐시로 사용된다면, 메인 메모리는 디스크의 캐시로 사용됨.
캐시 메모리와 DRAM의 관계에서 블록(Block)이라는 단위를 사용하듯이, 메인 메모리와 디스크의 관계에서는 페이지(Page)라는 단위를 사용함.
가상 페이지(Virtual Page) : 디스크에 위치하는 가상 주소 공간(Virtual Address Space)의 각 페이지
물리 페이지(Physical Page) : 메인 메모리에 위치하는 물리 주소 공간(Physical Address Space)의 각 페이지
DRAM 캐시(= 디스크의 캐시)는 캐시 메모리(= 메인 메모리의 캐시)에 비해 Miss Penalty가 매우 큼.
DRAM과 SRAM의 속도 차이는 10배 정도인 반면, 디스크와 DRAM의 속도 차이는 거의 10,000배에 이르기 때문.
정리
- 가상 메모리 매커니즘에 캐시가 필요함
- 그 캐시는 디스크에서 메인 메모리로 저장됨
- 그래서 가상메모리는 미스 페널티가 크다
9.3.2 페이지 테이블
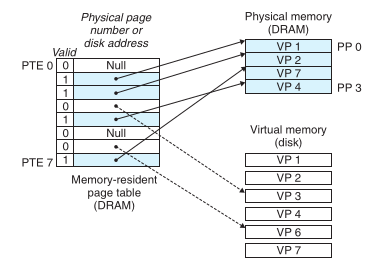
(8개의 가상 페이지와 4개의 물리 페이지를 갖는 시스템을 위한 페이지 테이블 예시)
페이지 테이블
- 가상 주소를 물리 주소로 변환하는 데 사용되는 데이터 구조
- 가상 페이지와 물리 페이지 사이의 맵핑 정보가 담김
- 메인 메모리의 커널 영역에 저장되는 자료 구조
- 각 프로세스마다 존재함. 문맥 전환을 수행할 때 저장하는 문맥 정보에도 페이지 테이블이 포함됨.
- 페이지 테이블 엔트리(PTE)의 배열
페이지 테이블 엔트리(PTE)에 담기는 정보
- 유효 비트(Valid Bit): 해당 페이지가 유효한지 여부
- 프레임 번호(Frame Number): 가상 페이지가 매핑된 물리 페이지 프레임의 번호
- 접근 권한 비트(Access Permission Bits): 페이지에 대한 읽기, 쓰기, 실행 권한을 제어함
- 사용 비트(Usage Bit): 페이지의 최근 사용 여부를 나타내어 페이지 교체 알고리즘에 사용됨
- 가상 페이지가 물리 페이지에 매핑되어 있지 않다면 디스크의 어느 위치에 존재하는지에 대한 정보
9.3.3 페이지 적중
접근하고자 하는 가상 주소에 해당하는 PTE의 Valid 비트가 1이면, 해당 가상 페이지가 물리 페이지에 맵핑되어 있음을 의미한다. 이를 페이지 적중(Page Hit) 또는 DRAM 캐시 적중이라고 부른다.
9.3.4 페이지 폴트 (page fault)
페이지 폴트 : 요청된 가상 페이지가 물리 메모리에 없는 경우
페이지 폴트가 발생하면
- 운영 체제가 페이지 폴트 처리하기 위해 제어를 넘겨받은 후
- 디스크에서 요청된 페이지를 찾아서 물리 메모리로 로드함
- 페이지 테이블 업데이트해서 새로운 페이지 프레임 번호랑 유효 비트 설정
- 페이지 폴트를 발생시킨 명령어를 재실행
9.3.5 페이지의 할당
malloc같은 걸로 힙 영역을 새로 할당하려 할 때
커널은 가상 페이지를 디스크에 할당한 뒤
PTE를 페이지 테이블에 새로 만들어준다.
9.3.6 문제해결을 위한 또 한 번의 지역성의 등장
시간적 지역성(Temporal Locality): 최근에 접근된 데이터가 다시 접근될 가능성이 높은 것
공간적 지역성(Spatial Locality): 접근된 데이터의 근처 데이터가 곧 접근될 가능성이 높은 것
아니 디스크에서 꺼내오는 거면 비효율적인거 아님?
-> 아님. 어차피 쓰는게 그게 그거라 괜찮음. 유식하게 말하면 지역성이 있음.
근데 사용하는게 물리 메모리보다 크거나 페이지 폴트가 너무 자주 발생하면
계속 디스크에서 넣었다 뺐다 해야됨.
이런 걸 쓰래싱(thrashing)이라고 함.
쓰래싱 방지 방법
- 적절한 페이지 교체 알고리즘 사용: LRU(Least Recently Used), FIFO(First In First Out) 등.
- 작업 집합 모델: 각 프로세스가 실제로 필요로 하는 페이지 집합을 메모리에 유지하도록 관리
- 물리 메모리 확장: 충분한 물리 메모리를 확보하여 페이지 폴트 발생을 줄임
- 프로세스 조정: 동시 실행 프로세스의 수를 조정하여 각 프로세스가 필요한 메모리를 충분히 할당받게 함
가상 메모리의 주요 목적
- 추상화와 메모리 보호:
- 각 프로세스가 자신의 독립된 메모리 공간을 가지고 있는 것처럼 보이게 하여 메모리 충돌을 방지합니다.
- 프로세스가 서로의 메모리 공간에 접근하지 못하게 하여 메모리 보호를 제공합니다.
- 효율적인 메모리 사용:
- 실제 물리 메모리보다 더 큰 주소 공간을 제공하여 프로세스가 더 많은 메모리를 사용하는 것처럼 보이게 합니다.
- 실제로 필요한 메모리만 물리 메모리에 로드하여 메모리를 효율적으로 사용합니다.
- 페이지 폴트와 디스크 I/O:
- 사용되지 않는 메모리 페이지를 디스크로 스왑 아웃(swap out)하고, 필요한 페이지를 다시 스왑 인(swap in)하여 물리 메모리의 사용을 최적화합니다.
- 페이지 폴트가 발생할 때 디스크에서 데이터를 로드하는 작업을 포함합니다.
캐싱과의 관계
가상 메모리는 기본적으로 디스크와 메모리 간의 캐싱 메커니즘입니다. 그러나 가상 메모리는 단순한 캐시 이상의 복잡한 기능을 수행합니다. 다음은 가상 메모리와 캐시의 차이점과 유사점을 나타낸 것입니다.
유사점
- 캐싱 메커니즘:
- 둘 다 더 빠른 접근을 위해 더 느린 저장 장치에서 데이터를 가져와 임시 저장하는 역할을 합니다.
- 페이지 테이블과 TLB(Translation Lookaside Buffer)는 가상 메모리에서의 캐시 역할을 합니다.
- 지역성의 활용:
- 둘 다 지역성의 원리를 활용하여 자주 사용되는 데이터를 더 빠른 저장 장치에 보관합니다.
- 시간적 지역성과 공간적 지역성을 활용하여 성능을 최적화합니다.
차이점
- 목적과 범위:
- 가상 메모리는 프로세스 간의 메모리 격리, 보호, 메모리 확장을 제공하는 것을 목적으로 합니다.
- 캐시는 주로 데이터 접근 속도를 높이기 위한 임시 저장 공간을 제공합니다.
- 관리 단위:
- 가상 메모리는 페이지 단위(보통 4KB 또는 8KB)로 메모리를 관리합니다.
- 캐시는 캐시 라인 단위(보통 64바이트)로 데이터를 관리합니다.
- 구현 수준:
- 가상 메모리는 운영 체제와 하드웨어(MMU)에 의해 구현됩니다.
- 캐시는 CPU 내부에서 하드웨어적으로 구현됩니다.
9.4 메모리 관리를 위한 도구로서의 가상메모리
여러 가상 페이지는 동일한 물리 페이지를 공유할 수 있음
가상 메모리와 독립된 가상 주소 공간의 조합은 시스템의 메모리 사용과 관리에 중요한 영향을 미침
가상 메모리는 링크 및 로딩, 코드 및 데이터 공유, 응용 프로그램의 메모리 할당을 단순화함
- 링킹 단순화 : 각 프로세스가 물리적 메모리의 실제 위치와 상관없이 동일한 기본 메모리 이미지 형식을 사용할 수 있도록 하여, 링크 및 로더의 설계와 구현을 크게 단순화함
- 로딩 단순화 : 실행 파일과 공유 객체 파일을 메모리에 쉽게 로드할 수 있음. 로더는 디스크에서 메모리로 데이터를 실제로 복사하지 않고, 가상 메모리 시스템이 처음 참조될 때 자동으로 데이터를 페이징함.
- 공유 단순화 : 운영체제는 사용자 프로세스와 운영체제 자체 간의 공유를 일관되게 관리할 수 있음. 여러 프로세스가 코드와 데이터를 공유해야 할 필요가 있음. 운영체제는 여러 프로세스가 동일한 물리 페이지를 가상 페이지로 매핑하도록 하여 이 코드를 공유할 수 있음.
- 메모리 할당 단순화 : 가상 메모리는 사용자 프로세스에 추가 메모리를 할당하는 간단한 메커니즘을 제공함. 사용자 프로세스가 추가 힙 공간을 요청하면, 운영체제는 적절한 수의 연속된 가상 메모리 페이지를 할당하고, 이를 물리 메모리의 임의의 물리 페이지에 매핑함. 페이지 테이블의 작동 방식 덕분에 운영체제가 연속된 물리 메모리 페이지를 찾을 필요가 없으며, 물리 메모리의 페이지들은 임의로 흩어질 수 있음.
9.5 메모리 보호를 위한 도구로서의 가상메모리
운영체제는 사용자 프로세스가 커널이나 다른 프로세스 메모리들이나 데이터들을 헤집고 다니지 않도록 제어해야 함.
가상 주소 공간을 제공하면 사적 메모리를 다른 프로세스로부터 분리하는 것이 쉬워짐. 물리적 메모리에서 프로세스 간의 메모리 충돌을 방지할 수 있음. 이로 인해 하나의 프로세스에서 발생한 오류가 다른 프로세스의 메모리에 영향을 미치지 않도록 보호할 수 있음.
주소 변환 하드웨어는 CPU가 주소를 생성할 때마다 페이지 테이블 엔트리(PTE)를 읽으므로, PTE에 추가적인 권한 비트를 추가하여 가상 페이지의 내용에 대한 접근을 제어하는 것이 간단함. 각 PTE를 읽고, SUP 비트가 설정되어 있는지를 확인하여 커널 모드인지 사용자 모드인지에 따라 접근을 제어할 수 있음.
9.6 주소의 번역
가상 메모리와 주소 번역
컴퓨터 시스템에서 가상 메모리는 물리적 메모리보다 더 큰 주소 공간을 제공하여, 물리 메모리와 가상 주소 공간 사이의 매핑을 관리함. 이 과정은 CPU가 가상 주소를 생성하고, 이를 물리 주소로 변환하여 메모리에 접근하는 방식으로 이루어짐. 이 주소 변환 작업은 CPU와 운영 체제의 협력을 필요로 함. CPU 칩의 메모리 관리 유닛(MMU)은 메모리에서 관리되는 페이지 테이블을 사용하여 가상 주소를 실시간으로 물리 주소로 번역함.
주소 공간 (Address Spaces)
주소 공간은 비음수 정수 주소의 정렬된 집합으로 정의됨. 시스템에서 가상 메모리를 사용하는 경우, CPU는 가상 주소 공간에서 가상 주소를 생성함. 가상 주소 공간은 n비트 주소 공간이라고 하며, 현대 시스템에서는 보통 32비트 또는 64비트 가상 주소 공간을 지원함. 물리 주소 공간은 시스템의 물리 메모리 바이트에 해당하며, 이를 통해 가상 메모리와 물리 메모리 간의 변환이 이루어짐.
주소 번역 속도 향상: TLB (Translation Lookaside Buffer)
CPU가 가상 주소를 생성할 때마다 MMU는 페이지 테이블 항목(PTE)을 참조하여 가상 주소를 물리 주소로 변환함. 최악의 경우, 이는 메모리에서 추가로 가져와야 하므로 수십에서 수백 사이클의 비용이 발생합니다. L1 캐시에 PTE가 캐시되어 있으면 비용이 몇 사이클로 줄어듦. 많은 시스템은 MMU에 TLB라는 작은 PTE 캐시를 포함하여 이 비용을 없애려고 함.
주소 번역 전체 과정
예시 : 가상 주소 0x03d4에서 바이트를 읽는 로드 명령
- MMU는 가상 주소에서 가상 페이지 번호(VPN)를 추출
- TLB에서 해당 PTE가 캐시되어 있는지 확인
- TLB에서 적중하면 캐시된 물리 페이지 번호(PPN)을 MMU에 반환
- 적중 안 하면 발생하면 MMU는 페이지 테이블에서 PTE를 가져옴
- 필요한 PTE가 유효하지 않으면 페이지 폴트가 발생하고 커널이 개입하여 필요한 페이지를 메모리에 로드함
9.8 메모리 매핑
리눅스는 가상 메모리 영역의 내용을 디스크의 객체와 연관시켜 초기화하는데, 이를 메모리 매핑(memory mapping)이라고 함. 메모리 매핑을 통해 두 가지 유형의 객체를 가상 메모리 영역에 매핑할 수 있음.
1. 리눅스 파일 시스템의 일반 파일
- 특정 파일을 메모리에 매핑하여, 파일을 읽거나 쓸 때 파일 입출력(I/O)을 직접 사용하는 대신 메모리에 접근하듯이 접근할 수 있게 함.
- 가상 메모리 영역은 실행 파일과 같은 일반 디스크 파일의 연속된 섹션에 매핑될 수 있음. 파일 섹션은 페이지 크기 조각으로 나뉘어져 있으며, 각 조각은 가상 페이지의 초기 내용을 포함함. 요구 페이징 덕분에 이러한 가상 페이지는 CPU가 해당 페이지를 처음 접근할 때까지 물리적 메모리로 전환되지 않음. 영역이 파일 섹션보다 크면, 해당 영역은 0으로 채워짐.
2. 익명 파일
- 익명 매핑은 파일과 연관되지 않은 메모리 매핑으로, 프로세스가 요청한 메모리 영역이 실제 물리 메모리나 스왑 공간과 연결됨.
- 가상 메모리 영역은 커널에 의해 생성된 익명 파일에 매핑될 수도 있으며, 이 파일은 모두 0으로 채워져 있다. CPU가 이러한 영역의 가상 페이지를 처음 접근할 때, 커널은 적절한 희생 페이지를 물리 메모리에서 찾아내고, 해당 페이지가 dirty하다면 스왑 아웃하고, 희생 페이지를 0으로 덮어쓴다. 그런 다음 페이지 테이블을 업데이트하여 페이지가 존재한다고 표시한다. 이 과정에서 디스크와 메모리 간에 실제 데이터 전송은 발생하지 않으므로, 이러한 페이지는 때때로 'demand-zero pages'라고 불린다.
디스크의 객체(파일 또는 스왑 공간)와 연결하여 초기화 한다는게 뭔 소린지 이해를 못하겠는데
디스크의 객체(파일 또는 스왑 공간)와 연결하여 초기화한다는 것은 가상 메모리의 특정 영역을 디스크에 있는 파일이나 스왑 공간과 연관 지어 사용하는 것을 의미합니다. 이 과정에서 메모리 매핑을 사용하여 파일의 내용을 메모리처럼 다룰 수 있게 합니다.
리눅스는 가상 메모리 영역의 내용을 디스크의 객체와 연관시켜 초기화하는데, 이를 메모리 매핑(memory mapping)이라고 함. 메모리 매핑을 통해 두 가지 유형의 객체를 가상 메모리 영역에 매핑할 수 있음.
가 의미하는게, 가상 메모리라는게 원래 디스크에 캐싱하는거잖아? 근데 그냥 캐싱하는게 아니라 원래 디스크랑 연관된 정보도 넣어서 읽기 쓰기도 할 수 있게 한다는건가? 근데 익명 파일은 왜 필요한거지 그럼?
가상 메모리 시스템은 물리 메모리보다 큰 주소 공간을 제공하며, 각 프로세스에 독립된 메모리 공간을 할당하여 메모리 보호와 효율성을 제공합니다. 메모리 매핑은 가상 메모리 주소를 물리 메모리나 디스크 상의 객체(파일 또는 스왑 공간)에 매핑하는 방법입니다.
- 파일 매핑 (File-backed Mapping):
- 디스크의 파일을 가상 메모리 주소 공간에 매핑하여 파일의 내용을 메모리처럼 다루게 합니다.
- 파일 입출력을 효율적으로 처리하며, 파일의 변경 사항이 메모리에 반영됩니다.
- 익명 매핑 (Anonymous Mapping):
- 특정 파일과 연관되지 않은 메모리 매핑으로, 순수한 메모리 할당을 제공합니다.
- 스왑 공간을 통해 물리 메모리보다 큰 메모리 공간을 사용할 수 있습니다.
- 주로 동적 메모리 할당, 스택 및 힙 확장, IPC에서 사용됩니다.
익명 매핑은 파일과 관계없이 순수한 메모리 할당을 위한 것이며, 가상 메모리 시스템에서 메모리를 효율적으로 사용하고 보호하기 위해 중요한 역할을 합니다. 파일 매핑과 익명 매핑은 각각의 사용 목적에 맞게 활용됩니다.
"원래 디스크랑 연관된 정보도 넣어서"라는 부분은 맞게 표현한 거임?
"원래 디스크랑 연관된 정보도 넣어서"라는 표현은 가상 메모리 시스템에서 파일 매핑을 설명할 때 적절한 표현입니다. 이를 통해 디스크에 저장된 파일의 데이터를 메모리 주소 공간에 매핑하여, 파일의 내용을 직접 메모리에 접근하듯이 사용할 수 있게 됩니다. 다시 말해, 파일 매핑을 통해 디스크의 파일과 가상 메모리 주소 공간을 연관시키는 것입니다.
정확한 표현
"가상 메모리 영역을 디스크의 파일과 연관지어 초기화함": 이는 파일 매핑을 의미하며, 메모리 주소 공간의 일부를 디스크 파일의 내용으로 초기화한다는 것을 의미합니다. 이 방식으로 디스크의 파일 내용을 메모리에서 접근할 수 있습니다.
9.8.1 다시 보는 공유 객체
메모리 매핑의 아이디어는 가상 메모리 시스템이 기존 파일 시스템과 통합될 수 있다면, 프로그램과 데이터를 메모리에 로드하는 간단하고 효율적인 방법을 제공할 수 있다는 통찰에서 비롯됨.
프로세스 추상화는 각 프로세스에 대해 독립적인 가상 주소 공간을 제공하며, 이는 다른 프로세스의 잘못된 쓰기 또는 읽기로부터 보호됨.
하지만 많은 프로세스는 동일한 읽기 전용 코드 영역을 가지고 있음. 예를 들어, 각 리눅스 쉘 프로그램 bash를 실행하는 프로세스는 동일한 코드 영역을 가짐. 공통 코드의 중복 복사본을 물리적 메모리에 보관하는 것은 매우 낭비임. 메모리 매핑은 여러 프로세스가 동일한 물리적 메모리 페이지를 공유할 수 있는 매커니즘을 제공함.
9.8.2 다시 보는 fork 함수
fork 함수가 호출되면
새로운 프로세스에 PID가 할당되고
새로운 프로세스의 가상 메모리를 생성하기 위해
현재 프로세스의 mm_struct, area struct, 페이지 테이블의 정확한 복사본을 생성하고
각 페이지를 읽기 전용으로 플래그 지정하고
각 area struct를 개인적인 copy-on-write로 플래그 지정한다.
fork가 반환되면 새로운 프로세스는 fork가 호출될 당시의 가상 메모리의 정확한 복사본을 가지게 된다.
이후 어느 프로세스가 쓰기를 수행하면 copy-on-write 메커니즘이 새로운 페이지를 생성하여 각 프로세스의 독립적인 주소 공간 추상화를 유지한다.
9.8.3 다시 보는 execve 함수
프로세스에서 execve("a.out", NULL, NULL)를 호출하면,
execve 함수는 현재 프로세스 내에서 실행 파일 a.out에 포함된 프로그램을 로드하고 실행함.
이를 위해 다음 단계가 필요함.
- 기존 사용자 영역 삭제. 현재 프로세스의 가상주소의 사용자 부분에 있는 기존 영역 구조체들을 삭제
- 사적 영역 매핑. 새로운 프로그램의 코드, 데이터, bss, 스택 영역에 대해 새로운 영역 구조체 생성
- 공유 영역 매핑. a.out 파일의 .text와 .data 섹션에 코드와 데이터 영역을 매핑
- 프로그램 카운터(PC) 설정. PC를 코드 영역의 진입점으로 설정
9.8.4 함수를 이용한 사용자수준 메모리 매핑
리눅스 프로세스는 mmap 함수를 사용하여 새로운 가상 메모리 영역을 생성하고, 이러한 영역에 객체를 매핑할 수 있다.
mmap 함수는 커널에 새로운 가상 메모리 영역을 생성하고, 파일 디스크립터 fd에 의해 지정된 객체의 연속된 조각을 새로운 영역에 매핑하도록 요청한다.
mmap 함수의 인자는 새로 매핑된 가상 메모리 영역의 접근 권한과 객체 유형을 설명한다. 예를 들어, MAP_PRIVATE | MAP_ANON 플래그를 사용하여 읽기 전용의 개인적인 demand-zero 영역을 생성할 수 있다.
9.9 동적 메모리 할당
가상메모리 영역을 저수준의 mmap과 munmap 함수를 사용해서 생성하고 삭제할 수 있지만,
C 프로그래머들은 가상메모리가 더 필요할 때 동적 메모리 할당기 쓰는게 더 편하다고 생각함.
동적 메모리 할당기는 프로세스의 가상메모리 영역인 힙(heap)을 관리함.
할당기는 힙을 다양한 크기의 블록들의 집합으로 관리함.
각 블록은 할당되었거나 사용 가능한 가상메모리의 묶음임.
명시적 할당기는 C에서 malloc 같은거임. free로 블록 반환해야 됨.
묵시적 할당기는 가비지 컬렉터임. 사용하지 않은 할당된 블록을 알아서 반환시켜줌.
9.9.1 malloc과 free 함수
C 표준 라이브러리는 malloc 패키지로 알려진 명시적인 할당기를 제공함.
프로그램은 malloc 함수를 호출해서 힙으로부터 블록들을 할당받음.
malloc 함수는 size 바이트의 메모리 블록에 대한 포인터를 반환함.
이 메모리 블록은 모든 데이터 객체를 저장할 수 있도록 정렬되어 있음.
만약 할당 중 문제가 발생하면, malloc은 NULL을 반환하고 errno를 설정함.
malloc 같은 동적 메모리 할당기는 mmap와 munmap 함수, 또는 sbrk 함수를 사용해서
명시적으로 힙 메모리를 할당하거나 반환한다.
sbrk 함수는 커널의 brk 포인터에 incr을 더하여 힙을 확장하거나 축소함.
성공 시 이전 brk 값을 반환하며, 실패 시 -1을 반환하고 errno를 ENOMEM으로 설정함.
프로그램들은 free 함수를 사용하여 할당된 힙 블록을 해제함.
9.9.2 왜 동적 메모리 할당인가?
동적 메모리 할당을 사용하는 가장 중요한 이유는 프로그램이 실제로 실행될 때까지 특정 데이터 구조의 크기를 알 수 없는 경우가 많기 때문임.
9.9.3 할당기 요구사항과 목표
명시적 할당기는 몇 가지 엄격한 제약 조건 내에서 작동해야 함
- 임의의 요청 순서 처리하기: free에 대응되는 블럭이 있어야 한다는 제약 조건을 제외하고, 할당기는 할당과 반환 요청의 순서에 대해서 아무 가정도 할 수 없음. 크기, 순서같은 거 막 들어올 수 있음.
- 요청에 대한 즉각적인 응답: 메모리 할당된 블록은 특정 데이터 유형에 종속되지 않고, 어떤 유형의 데이터도 저장할 수 있어야 함.
- 힙만 사용: 필요에 따라 크기를 조절하기 위해 할당기가 사용하는 모든 비확장성 자료 구조는 힙에 저장되어야 함.
- 블록 정렬: 할당기는 모든 유형의 데이터 객체를 저장할 수 있도록 블록을 정렬해야 함.
- 할당된 블록 수정 금지: 할당기는 가용 블록만 조작하거나 변경할 수 있음. 일단 블록이 할당되면 수정하거나 이동할 수 없음. 따라서 할당된 블록을 압축하는 등의 기술은 허용되지 않음.
할당기 개발할 땐 이러한 제한들과 함께 처리량과 메모리 이용도를 최대화해야됨.
근데 처리량과 메모리 이용도는 서로 반비례함. 그래서 만들기 어려움.
목표 1 : 처리량 극대화하기. 일반적으로, 할당과 반환 요청들을 만족시키기 위한 평균 시간을 최소화해서 처리량을 최대화함. 할당 요청의 최악 실행 시간이 가용 블록의 수에 비례하고, 반환 요청의 실행시간이 상수인, 적당히 좋은 성능의 할당기를 만드는 건 쉬움.
목표 2 : 메모리 이용도 최대화. 잘 모르면 가상메모리가 무한 자원이라고 착각하기 쉬움. 사실 한 시스템에서 모든 프로세스에 의해 할당된 가상메모리의 양은 디스크 내의 스왑 공간의 양에 의해 제한됨. 큰 크기의 메모리 블록을 할당하고 반환할 것을 요청받는 동적 메모리 할당기의 경우 특히나 그러함.
9.9.4 단편화
가용 메모리가 할당 요청 못 만족시키는 상태
내부 단편화: 할당된 블록이 실제로 필요한 용량보다 클 때
외부 단편화: 총 메모리는 여유 있는데, 단일 여유 블록이 할당 요청을 처리할 만큼 크지 않음
9.9.5 구현 이슈
실용적인 할당기는 다음과 같은 이슈를 고려해야 함.
- 여유 블록 조직: 여유 블록을 어떻게 추적할 것인가?
- 배치: 새로 할당된 블록을 어떤 여유 블록에 배치할 것인가?
- 분할: 새로 할당된 블록을 여유 블록에 배치한 후 남은 여유 블록을 어떻게 처리할 것인가?
- 병합: 방금 해제된 블록을 어떻게 처리할 것인가?
9.9.6 묵시적 가용 리스트
할당기가 블록 경계를 구분하고 할당된 블록과 여유 블록을 구별하는 데이터 구조가 필요하다.
대부분의 할당기는 이 정보를 블록 자체에 포함시킨다.
간단하게는 블록 헤더에 블록 크기와 할당 상태를 인코딩하면 된다.
9.9.7 할당한 블록의 배치
프로그램이 k 바이트의 블록을 요청할 때 할당기는 해당 요청을 처리할만큼 큰 여유 블록을 찾는다.
할당기가 검색하는 방법은 배치 정책에 의해 결정된다.
배치 정책에는 first fit, next fit, best fit이 주로 사용된다.
- First Fit: 여유 리스트의 시작부터 검색하여 맞는 첫 번째 여유 블록을 선택한다.
- 장점 : 큰 여유 블록을 리스트의 끝에 보존할 수 있다
- 단점 : 작은 여유 블록이 리스트의 시작 부분에 남아 있어 더 큰 블록을 검색하는 시간이 길어질 수 있다
- Next Fit: First Fit과 유사하지만, 각 검색을 리스트의 시작이 아닌 이전 검색이 끝난 지점부터 시작한다.
- 장점 : First Fit보다 빠르게 작동할 수 있다
- 단점 : 메모리 사용률이 더 낮을 수 있다
- Best Fit: 모든 여유 블록을 검사하여 맞는 가장 작은 여유 블록을 선택한다.
- 장점 : 메모리 사용률이 높다
- 단점 : 단순한 리스트 구조에서는 힙의 모든 블록을 검색해야 한다
9.9.8 가용 블록의 분할
여유 블록 찾으면 얼마나 할당할지 정해야 됨.
가용 블록 다 쓰면 내부 단편화(할당된 블록이 실제로 필요한 용량보다 큼)가 생김
크기가 안 맞으면 가용 블록을 두 개로 나눈 다음 한쪽에 할당한다.
9.9.9 추가적인 힙 메모리 획득하기
여유 블록이 없으면 일단 물리적으로 인접한 가용 블록들을 합쳐본다.
그래도 없으면 sbrk 함수로 커널에 추가 힙 메모리 요청하고 거기에 넣는다.
9.9.10 가용 블록 병합하기
할당된 블록 반환하다보면 가용 블럭들이 작게 쪼개져서 효율이 좋게 쓰기 어려워짐.
다 작아서 못 넣는걸 오류 단편화(false fragmentation)라고 함.
이땐 병합 정책에 따라 병합하면 됨.
- 즉시 병합: 블록이 해제될 때마다 인접한 블록을 즉시 병합합니다.
- 지연 병합: 나중에 병합을 수행함. 예를 들어, 할당 요청이 실패할 때까지 기다렸다가 병합을 수행함.
즉시 병합하면 간단하긴 한데 어떨 땐 블록 합쳤다가 쪼갰다가 반복하는 비효율 유발할 수도 있음
9.9.11 경계 태그를 이용한 병합
병합 구현할 때 경계 태그 쓸 수 있음.
반환 하려는 블록의 헤더가 다음 블록의 헤더를 가리키면
다음 블록이 가용한지 체크할 수 있음.
근데 다음 블록은 어딨는지 안다고 쳐도 이전 블록을 병합하려고 할 땐 어케 해야됨?
-> 경계 태그를 쓰면 됨.
경계 태그는 그냥 블록 끝에 header를 복사한 footer를 추가하는 거임.
header랑 footer랑 똑같은데 뭔 의미냐고?

여기서 n 위에 있는 m1이 없다고 해보셈.
m1이 어디까지인지 알 수 있음? 없음.
일일이 메모리 탐색하면서 어디까지 블럭이 있는지 확인해야됨.
근데 n 위에 m1이 있으면 다음 m1이 어디에 있는지 알 수 있음.
이전 블럭의 크기가 얼마인지 바로 알 수 있다는 말임.
이렇게 경계 태그를 이용하면 병합을 좀 더 빠르게 할 수 있음.
근데 header랑 footer가 필요하므로 자주 쓰는 작은 블록을 다루면 비효율 일어날 수 있음.
근데 이것마저도 하위 비트들은 footer 안 넣는 식으로 하면 해결 가능.
9.9.13 명시적 가용 리스트
묵시적 가용 리스트는 기본적인 할당기 개념을 도입하는 데는 유용하지만,
힙 블록의 총 수에 비례하여 블록 할당 시간이 선형으로 증가하므로 일반 목적의 할당기에는 적합하지 않다.
명시적 가용 리스트는 이러한 단점을 극복하기 위해 고안되었다.
명시적 가용 리스트에서는 가용 블록을 명시적 데이터 구조로 조직한다.
가용 블록의 안 쓰는 부분에 가용 블록들의 정보들을 저장한다는 뜻이다.
힙을 이중 연결 리스트로 구성한다면, 각 가용 블록에는 pred(이전 블록)와 succ(다음 블록) 포인터를 포함시킨다.
이중 연결 리스트를 사용하면 First fit 할당 시간이 힙 블록의 총 수에 비례하는 것이 아니라 가용 블록의 수에 비례하게 줄어든다. 그러나 블록 해제 시간은 블록을 해제할 때 선택한 정책에 따라 선형 시간이 될 수도 있고 상수 시간이 될 수도 있다.
가용 블록 정렬하는 주요 방법
- LIFO 순서 : 새로 해제된 블록을 리스트의 시작 부분에 삽입한다. LIFO 순서와 First fit 배치 정책을 사용하면 가장 최근에 사용된 블록을 먼저 검사하게 된다. 이 경우, 블록 해제는 상수 시간에 수행될 수 있으며, 경계 태그를 사용하면 병합도 상수 시간에 수행될 수 있다.
- 주소 순서: 리스트에 있는 각 블록의 주소가 그 다음 블록의 주소보다 작도록 정렬한다. 이 경우, 블록을 해제하려면 적절한 이전 블록을 찾기 위해 선형 시간 검색이 필요하다. 주소 순서 First fit 배치는 LIFO 순서 First Fit 배치보다 메모리 활용도가 높아질 수 있다.
명시적 리스트의 단점은 가용 블록이 필요한 모든 포인터뿐만 아니라 헤더와 푸터를 포함할 만큼 충분히 커야 한다는 점이다. 이는 최소 블록 크기를 증가시키고 내부 단편화의 가능성을 높인다.
9.9.14 분리된 가용 리스트
분리된 가용 리스트(segregated free list)는 할당 시간을 줄이기 위한 일반적인 접근 방식이다.
단일 연결 가용 블록 리스트 쓰면 한 개의 블록을 할당하는 데 가용 블록의 수에 비례하는 시간이 필요하니까
쪼개서 저장하는 거.
간단히 분리된 저장소
다 똑같은 크기로 분리.
할당과 해제가 빠른 상수 시간 작업이지만,
가용 블록이 절대 분할되지 않으므로 내부 단편화가 발생할 수 있고,
특정 참조 패턴이 실행될 때 외부 단편화에 취약하다.
분리 맞춤
할당기가 크기 클래스와 연관된 가용 리스트 배열을 유지한다.
각 가용 리스트는 크기 클래스의 멤버인 다른 크기의 블록을 포함할 수 있다.
검색 시간이 특정 힙 부분으로 제한되므로 전체 힙을 검색할 필요가 없기 때문에 시간이 줄어든다.
버디 시스템
분리 맞춤의 특별한 경우. 각 크기 클래스가 2의 제곱이다.
블록들의 버디 주소가 한 비트 위치만 달라서 쓰는듯.
근데 내부 단편화가 심함. 특정 프로그램에선 유용할 수 있다.
9.10 가비지 컬렉션
가비지 컬렉터 : 프로그램에서 더 이상 사용하지 않는 블록들을 자동으로 반환하는 동적 저장장치 할당기
9.10.1 가비지 컬렉터 기초
가비지 컬렉터는 메모리를 도달 가능성 그래프(directed reachability graph)로 본다.
그래프의 노드는 루트 노드와 힙 노드로 나뉜다.
루트 노드는 힙이 아닌 위치를 가리키며, 힙으로의 포인터를 포함하는 위치다.
각 힙 노드는 힙에 할당된 블록에 해당된다.
p → q의 방향을 갖는 간선은 블록 p의 위치에서 블록 q의 위치를 가리키는 포인터가 있음을 의미한다.
노드 p가 도달 가능하다고 말하는 경우, 이는 어떤 루트 노드에서 p까지의 경로가 존재함을 의미한다.
어느 시점에서든 도달 불가능한 노드는 프로그램에서 다시 사용할 수 없는 가비지에 해당한다.
가비지 컬렉터의 역할은 도달 가능성 그래프의 표시를 관리하고 주기적으로 도달 불가능한 노드를 free시키는 것이다.
9.10.2 Mark&Sweep 가비지 컬렉터
마크 앤 스윕 가비지 컬렉터는 마크 단계와 스윕 단계로 구성된다.
마크 단계에서는 모든 루트 노드의 도달 가능하고 할당된 하위 노드들을 표시한다.
스윕 단계에서는 표시되지 않은 블록들을 해제한다.
9.10.3 C 프로그램에 대한 보수적 Makr&Sweep
Mark&Sweep은 C에서 가비지 컬렉팅할 때 적절한 방법이다.
블록을 이동시키지 않은 채로 동작하기 때문에,
C 언어처럼 포인터를 직접 사용하고, 객체의 주소를 자주 참조하는 언어에서 유용하다.
객체의 주소가 변하지 않기 때문에 포인터를 다시 설정할 필요가 없다.
근데 C 언어에선 isPtr 함수를 구현하는게 어렵다.
어려운 이유
- C는 메모리 위치에 타입 정보를 기록하지 않음. 그래서 isPtr은 입력 매개변수가 포인터인지 아닌지 결정할 수 있는 명확한 방법이 존재하지 않음.
- p가 포인터였다는 걸 알게 돼도 isPtr이 p가 할당된 블록의 데이터 중에서 어떤 위치를 가리키는지 여부를 결정할 확실한 방법이 없음.
할당된 블록의 집합을 균형 이진 트리로 유지하면 해결됨.
모든 블록이 왼쪽 서브트리에 있는 경우 작은 주소에 있고,
오른쪽 서브트리에 있는 경우 큰 주소에 있음이 보장됨.
isPtr은 이 트리를 사용해서 할당된 블록을 이진 검색함.
매 단계에서 블록 헤더의 size 필드를 사용해서 p가 블록 내에 들어가는지 결정함.
접근할 수 있는 걸 다 mark할 수 있긴 한데
실제 도달할 수 없는 블록들을 잘못 mark할 수도 있음. (그래서 보수적)
일부 가비지 못 반환할 수도 있음.
9.11 C 프로그램에서의 공통된 메모리 관련 버그
가상메모리 사용하고 관리할 때 에러 생기기 쉬움.
잘못된 데이터를 잘못된 위치에 기록하면,
프로그램이 오랫동안 돌아가다가 한참 뒤에야
이 프로그램에서 멀리 떨어진 부분에 가서 마침내 실패한다.
9.11.1 잘못된 포인터의 역참조
어떤 프로세스의 가상 주소공간 내에 어떤 의미 있는 데이터로도 매핑되지 않은 큰 구멍들이 존재한다.
만약 포인터를 이 구멍들 중 하나로 역참조하려 하면 segmentation 예외가 일어난다.
또, 일부 가상메모리는 읽기만 가능하다. 이 영역에 쓰려고 하면 보호 예외로 프로그램을 종료시킨다.
잘못된 포인터의 예시
- NULL 포인터 역참조: 포인터가 NULL을 가리킬 때 이를 역참조하는 경우
- 해제된 포인터 역참조: 이미 해제된 메모리 블록을 가리키는 포인터를 역참조하는 경우
- 초기화되지 않은 포인터 역참조: 초기화되지 않은 포인터 변수를 사용하여 메모리에 접근하는 경우
scanf("%d", &val);으로 주소값을 제대로 전달해줘야 되는데
scanf("%d", val);그냥 값 전달하는 실수 종종 하니까 조심.
val이 유효한 주소값이어서 이상한 메모리 건드리면
치명적이고 혼란스러운 결과를 맞이하게 됨. 그것도 한참 나중에.
9.11.2 초기화되지 않은 메모리를 읽는 경우
int *y = (int *)malloc(n*sizeof(int));
for(i=0; i<n; i++)
y[i] += 1;배열 y가 0으로 초기화됐다고 잘못 가정해버리면 이렇게 된다.
명확하게 y[i]를 0으로 초기화하거나 calloc을 사용해야 한다.
9.11.3 스택 버퍼 오버플로우 허용하기
스택 버퍼 오버플로우는 지역 변수가 할당된 메모리 범위를 초과하여 쓰기 작업을 수행하는 경우 발생함.
이는 스택의 다른 변수나 반환 주소를 덮어쓸 수 있어 프로그램의 흐름을 변경하거나 보안 취약점을 초래할 수 있음.
9.11.4 포인터와 이들이 가리키는 객체들이 같은 크기라고 가정하기
int i;
int **A = (int **)malloc(n * sizeof(int));
for (i=0; i<n; i++)
A[i] = (int *)malloc(m * sizeof(int));sizeof(int)가 아니라 sizeof(int*)를 했어야 함.
이 코드는 int와 int 포인터가 같은 크기인 머신에서는 잘 돌아갈 것.
하지만 코어 i7같이 포인터가 int보다 더 큰 머신에서 돌리면 오류 남.
9.11.5 Off-by-One 에러 만들기
int array[10];
for (int i = 0; i <= 10; i++) { // 배열 경계를 벗어남
array[i] = i;
}배열 범위 넘어가는거
9.11.6 포인터가 가리키는 객체 대신에 포인터 참조하기
*size--;이래버리면 실제로 가리키는 정수 값 대신에 포인터 자신을 감소시킴.
(*size)--;이렇게 해야지 size가 갖고 있는 주소값에 들어있는 값을 1 줄임.
9.11.7 포인터 연산에 대한 오해
int arr[5] = {1, 2, 3, 4, 5};
int *ptr = arr;
ptr += 1; // 포인터는 4바이트(정수 크기)만큼 증가포인터에 대한 산술연산은 이들이 가리키는 객체의 크기 단위로 수행됨.
바이트 단위로 이루어지는게 아님.
9.11.8 존재하지 않는 변수 참조하기
int *foo() {
int x = 10;
return &x; // 잘못된 사용, 함수 반환 후 x는 유효하지 않음
}스코프를 벗어난 변수를 참조할 때 발생.
특히 함수가 반환한 후 해당 함수의 지역 변수를 참조하는 경우가 있음.
9.11.9 해제된 힙 블록을 참조
int *ptr = (int *)malloc(sizeof(int) * 10);
free(ptr);
*ptr = 10; // 잘못된 사용, 이미 해제된 메모리 접근이미 free된 힙 블록을 참조할 때 발생함.
이는 이중 해제(double free) 버그로 이어질 수 있으며,
시스템 충돌이나 예기치 않은 동작을 초래할 수 있음.
9.11.10 메모리 누수 유발
할당된 블록들은 반드시 반환해야 함.
'📚 Book > CS:APP' 카테고리의 다른 글
| CSAPP : 8장 예외적인 제어흐름 (0) | 2024.08.11 |
|---|---|
| CSAPP : 7장 링커 (0) | 2024.08.06 |
| CSAPP : 3장 프로그램의 기계수준 표현 (0) | 2024.08.06 |
| CSAPP : 1장 컴퓨터 시스템으로의 여행 (0) | 2024.08.06 |